구체적인 단어 찾기
어떤 글이 이해하기 쉬울까? 다양한 요소가 있겠으나, 일반적으로 추상적인 내용보다는 손에 잡힐 듯 구체적인 글이 더 잘 이해되는 것 같다. 그럼 어떤 문서가 얼마나 구체적인지를 측정할 수는 없을까?
올해 WSDM 컨퍼런스에 일본 연구자들이 발표한 Estimating content concreteness for finding comprehensible documents라는 논문을 보면, 일단 가능성은 열려 있는 것 같다. 이들은 단어 단위로 다양한 특성을 분석해서 그 단어의 구체적인 정도(Concreteness)를 계산한 뒤, 이를 바탕으로 그 단어가 포함된 문서의 구체성을 측정했다.
단어가 구체적인지 추상적인지는 어떻게 알 수 있을까? 여태껏 그래왔듯이, 이번에도 상관관계를 이용한다. 구체적인 단어는 어떤 (측정 가능한) 특성을 가질지, 또 추상적인 단어는 어떨지 직관을 이용해서 가설을 수립하고, 그렇게 측정한 요소값을 정답셋에 갈아넣고 머신러닝 방망이를 휘두르면 결과가 나온다.
단어의 구체성 자질
이 논문에서는 단어 단위 자질(Feature)을 크게 8가지로 나누었다.
- 사진이나 이미지를 묘사할 때 (가령, 이미지 검색이나 플리커 사진 태그) 얼마나 많이 사용되는가?
- 그 단어와 관련된 이미지의 태그가 얼마나 다양한가? 예를 들어, “행복”으로 검색했을 때 나오는 이미지와 “자전거”로 검색했을 때 나오는 이미지 중 어느쪽에 달린 태그가 더 다양할까?
- 보다, 듣다, 만지다 같은 동사와 많이 쓰였는가?
- 뜻이 다양한가? (WordNet 기준으로 “reason”이나 “life”처럼 추상적인 단어가 “tree”, “plant”같이 구체적인 단어보다 더 많은 의미를 가진다.)
- 단어에 관련된 감정(Sentiment)이 긍정적인가, 부정적인가, 아니면 중립적인가? 추상적인 단어에 긍정적이거나 부정적인 감정이 연관된 경우가 많고, 반대로 구체적인 단어는 중립적일 것 같지 않은가? “opportunity”, “regret” vs “desk”, “watch”)
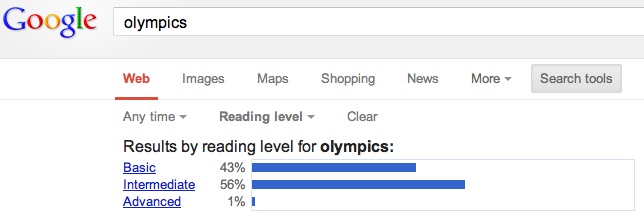
뭐 대충 이런 것들이다. 그런데 이렇게 공들여서 단어와 문서의 구체성을 계산하면 어디에 써먹을까? 한 가지 예는 검색 랭킹이다. 검색 쿼리에 따라,사용자에 따라 적당한 수준의 문서를 찾기 위한 요소로 활용할 수 있을 것이다. 실제로 구글은 Search tools 메뉴를 통해서 읽기 수준에 따른 문서 필터링 기능을 제공하고 있다.