LDA(Latent Dirichlet Allocation): 겉핥기
배경 설명
정보검색에서 문서 모델링은 중요한 의미가 있다. 간단하게 말하면, 문서 모델링이란 개별 문서 더 나아가 문서 컬렉션(Corpus)를 표현하는 방법을 찾는 것이다. 다양한 활용분야가 있겠지만 주제 분류나 문서 간 유사도 계산 등에 많이 쓰인다.
Generative Model
어떤 확률분포와 그 파라미터가 있다고 할 때, 그로부터 랜덤 프로세스에 따라 데이터를 생성하는 관점의 모델이다. 문서 모델링의 말로 설명하면, 문서의 주제 분포와 각 주제별로 특정 단어를 생성할 확률을 알고 있으면, 특정 문서가 만들어질 확률을 계산할 수 있다는 얘기다.
개념 학습
Latent Dirichlet Allocation이란?
LDA(Latent Dirichlet Allocation)는 문서 같은 데이터의 집합에 대한 Generative Probabilistic Model이다. 이건 정의도 아니거니와 LDA에 대해 별로 설명도 안 되니까 그냥 처음부터 구체적인 과정을 살펴보자. 아래는 모델에서 하나의 문서를 생성하는 절차를 보여준다.
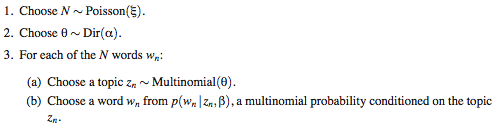
여기서 α와 β는 코퍼스 단위로 정해지는 값이고, N과 θ는 문서 단위로 정해지는 값이다. β는 각 주제별로 특정 단어가 생성될 확률이 담긴 테이블(2차원 매트릭스)이며, N은 문서의 길이, θ는 해당 문서에서 각 주제의 가중치를 나타낸다. (θ의 각 엔트리 값을 합치면 1이 된다.) zi는 문서의 i번째 단어에 대한 주제 벡터(하나의 엔트리만 1이고 나머지는 0)이다. 이 모델에서 주제의 개수는 k로 고정되어 있으며, 따라서 θ와 zi는 길이가 k인 벡터이다.
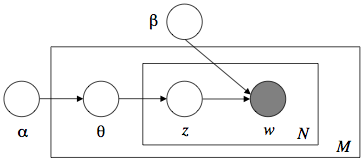
정리하면, 어떤 문서에 대해 파라미터 θ(주제 벡터)가 있고, 앞에서부터 단어를 하나씩 채울 때마다 θ로부터 하나의 주제를 선택하고, 다시 그 주제로부터 단어를 선택하는 방식으로 문서 생성 과정을 모델링하는 것이다. 사람이 실제로 글을 쓰는 과정하고는 완전히 다른 얘기이므로 헷갈리지 말자. 위 그림은 이 과정을 요약한 것이다.
이게 무슨 의미가 있는가?
이런 Generative Model을 써서 우리가 새로운 글을 쓰려는 건 당연히 아니다. 하지만, 이런 방법으로 문서 내용을 성공적으로 모델링, 즉 표현할 수 있다면 이미 존재하는 문서의 파라미터 θ를 찾아내는 것도 가능할 것이다. 글 d1과 d2가 있을 때, 주제는 비슷하더라도 각 문서에 등장하는 단어의 종류나 빈도는 다를 수 있기 때문에 단순한 키워드 기반의 모델로는 유사도를 계산하거나 주제 분류를 하는 데에 한계가 있다. 그러나 이미 보유한 많은 텍스트에 기초에 α와 β를 알아 두고, 개별 문서의 θ를 계산할 수 있다면, 이 θ를 가지고 유사도 계산이나 분류 작업을 훨씬 쉽고도 정확하게 해낼 수 있다.
이름의 의미
Latent Dirichlet Allocation이라는 이름에 담긴 뜻을 짚어보자.
- Latent: 사전적인 의미는 “잠재적인, 숨어 있는”. 위에서 설명한 과정에서 우리가 직접 관찰할 수 있는 것은 문서 내용뿐이다. α, β, θ, z는 모두 감춰진 파라미터이다.
- Dirichlet: 19세기 독일 수학자의 이름. 디리클레 분포(Dirichlet Distribution)가 그의 이름을 따서 지어졌다고 한다. 제일 위의 코드를 보면 θ를 결정할 때 α를 파라미터로 갖 디리클레 분포을 사용하고 있는데, 그 이유는 뒤에서 다시 살펴보겠다.
- Allocation: 말 그대로 ‘할당’. 각 단어를 결정할 때, θ에 대한 다항 분포(Multinomial Distribution)로 주제를 ‘할당’한 뒤 그 주제로부터 단어를 뽑는다. LDA의 개념이나 활용에서 여러 가지 할당이 나오므로 해석은 마음껏.
파라미터 추정
본격적으로 수식이 나와서 어려워지는데, 간단하게 의미만 짚어보자. (자세한 것은 LDA 파라미터 추정: 깁스 샘플링을 써서 글을 참고)
왜 디리클레 분포인가?
앞서 설명한 내용을 수식으로 적으면 아래와 같다.
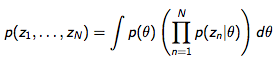
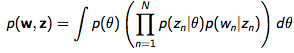
첫 번째 식은 문서의 주제 생성, 두 번째 식은 문서의 주제와 단어 생성을 나타낸다. 문서 주제(=내용)를 나타내는 z는 θ에 대한 조건부 확률이다. 베이즈룰(Bayes Rule)을 떠올려보자.
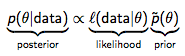
우리가 결국 하고 싶은 일은 문서 내용(위 식의 data)으로부터 θ를 추정하는 것이다. 위에서 Posterior라고 된 부분이 어떤 분포를 따르는지 알고 있으면 이 작업이 그나마 좀 쉬워지고, Conjugate Prior의 필요성이 바로 여기에서 나온다. 위 수식에서 Posterior와 Prior가 동일한 분포를 따르면, Prior를 Likelihood의 Conjugate Prior라고 한다. 중간에 Likelihood라고 된 부분은 θ에 대한 다항분포라고 앞에서 얘기했다. 그럼 다항분포의 Conjugate Prior가 뭘까? 바로 디리클레 분포다.
모델 단순화
이름에 대한 마지막 의문이 풀렸으니 계속 θ를 찾아보자. 코퍼스 레벨의 α와 β를 아는 상태에서 문서 w가 주어졌을 때, θ와 z에 대한 조건부 확률을 아래와 같이 쓸 수 있다.
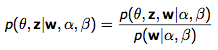
그런데 이걸 계산하는 게 Intractable 하다네? 그래서 어쩔 수 없이 모델을 단순화한다, 아래 그림처럼. (위의 그림과 비교해보자.)
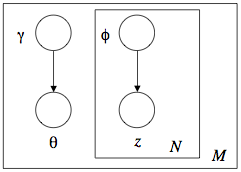
기껏 θ와 z의 관계를 설명하더니 이제 와서 두 개를 γ와 φ로 완전히 분리해버렸다. 그런데 이게 뜬금없는 건 아니고, Variational Inference라고 해서, 아래와 같이 q로 Variational Distribution을 표기하고,
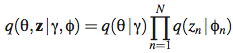
원래의 분포와 Variational Distribution 사이의 (두 분포 사이의 거리를 의미하는) KL divergence를 최소화하는 Variational Parameter(=γ와 φ)를 찾아내는 알고리즘이 있다고 한다. 자세한 내용이 궁금하면 LDA를 소개한 논문인 참고자료1의 부록을 참고하자. 이렇게 γ와 φ를 구한 뒤, 다시 이 값과 관찰된 문서를 사용해서 α와 β까지 추정한다. (γ와 φ를 구하는 과정을 E-Step, α와 β를 구하는 과정을 M-Step으로 놓고, EM 알고리즘을 쓴다. 역시 자세한 건 참고자료를..) 이런 식으로 코퍼스의 α와 β, 그리고 개별 문서에 대해 (θ와 z는 아니지만) γ와 φ를 구한다고 한다.
결과
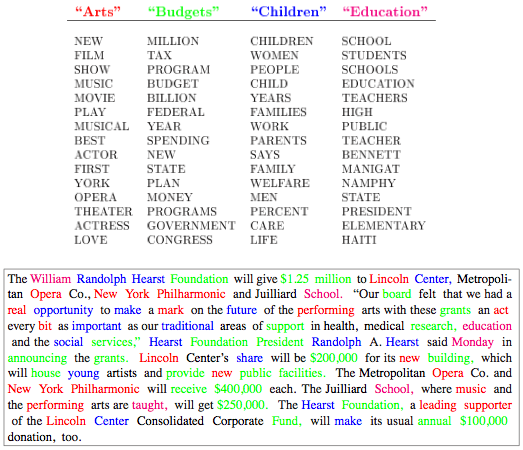
LDA를 설명할 때 자주 나오는 그림이다. 윗부분은 주제별로 관련성이 높은 단어를 뽑은 것, 즉 β이고, 아랫부분은 예제 문서에서 주제가 확실한 단어에 색칠한 것, 즉 φ를 보여준다. 윗부분에서 주제 이름(Arts, Budgets, Children, Education)은 알고리즘이 자동으로 뽑아주는 것이 아니라 사람이 정한 것이다. 비슷한 단어들이 엮여 나오기 때문에 문서 모델링 뿐 아니라 키워드 클러스터링에도 LDA를 써먹을 수 있다. 사실 LDA는 문서를 다룰 때만 쓰이는 것이 아니라, 비슷한 형태의 모든 데이터 분석에 활용할 수 있다. 이렇게 결과로 나온 특징(Feature)을 써서 문서 분류 등에 활용한 결과가 역시 참고자료1에 많이 나온다.
참고자료
- Latent Dirichlet Allocation, David M. Blei, Andrew Y. Ng, Michael I. Jordan, Journal of Machine Learning Research 3, 993 - 1022, 2003
- http://www.pletscher.org/academics/undergraduate/talks/lda-slides.pdf, Patrick Pletscher, 2005
- Dirichlet distribution - Wikipedia