스포츠 기사를 작성하는 알고리즘
최근에 관심이 가는 분야는 (스포츠) 기사를 자동으로 작성하는 기술이다. 몇 년 전 그런 스타트업이 나왔다는 얘기를 들었는데, 소프트웨어 로봇이 기자를 대체한다를 보니 일부 도메인에서는 이미 상용화 단계에 들어선 모양이다. 컴퓨터 알고리즘으로 기사를 쓰다니, 어떻게 하는 걸까?
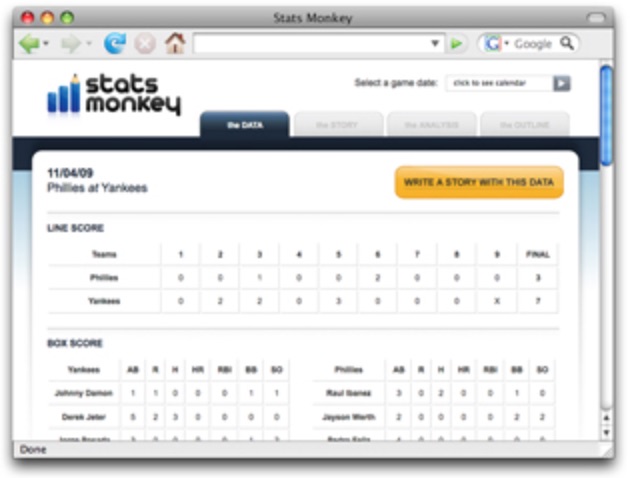
위 링크에서 언급된 내러티브 사이언스(Narrative Science)의 홈페이지를 보면, 노스웨스턴 대학교의 연구 프로젝트인 StatsMonkey가 전신이라는 것을 알 수 있다. 프로젝트의 결과물을 보고 거기에 참여했던 학생과 지도교수가 창업한 것이다. 핵심 기술은 회사의 영업 비밀이니 당연히 비공개지만 2010년 AAAI 컨퍼런스의 심포지엄에 발표된 StatsMonkey: A Data-Driven Sports Narrative Writer를 보면 개략적인 방법론을 추측할 수 있다.
진짜 사람이 쓴 것같은 기사를 만들려면 이벤트를 단순히 나열하는 걸로는 부족하다. 그 경기에서 중요했던 이벤트/선수를 찾아서 강조해야 하고, 이들을 부드럽게 연결해서 스토리를 만들어야 한다. 그 결과는 매끄러운 문장으로 제공되어야 한다.
경기의 주요 포인트를 찾아내기
먼저 경기의 하이라이트를 찾기 위해서 원본데이터(Raw Data)를 가공하여 아래와 같이 의미있는 수치를 만들었다고 한다.
- Win Probability: 과거 기록에 기반했을 때, 주어진 상황에서 승리할 확률 (“8회 1점 뒤지는 상황에서 상대 투수는 누가 나왔고 타선은 몇 번 누구부터 시작할 때, 이길 확률” 이런 게 아닐까)
- Leverage Index: 특정 플레이가 Win Probability를 바꾼 정도. 가령, 위의 상황에서 선두타자가 안타를 치고 나갔다면 Win Probability가 조금 상승했을 것이다. 그 다음 타자가 역전 2점 홈런을 쳤다면 Win Probability는 드라마틱하게 상승했을 것이고, 이 차이가 Leverate Index인 것 같다. 이 값을 이용하면 경기에서 가장 결정적인 순간/플레이들을 자동으로 찾을 수 있다.
- Game Score: 설명이 모호하지만, 선수 단위로 통계를 내서 주목할 만한 기록을 찾는 게 아닐까 싶다. 누가 퍼펙트게임을 달성할 뻔했다거나 홈런을 두 개나 쳤다거나 하는.
관점을 만들고 스토리를 작성하기
경기의 하이라이트를 나열한다고 기사가 되는 것은 아니다. 주요 이벤트를 모으고, 거기에 맥락을 불어넣어서 스토리로 만들어야 한다. 저자들이 설명하는 핵심 개념은 “Angle”이다. 저널리즘에서 용어를 빌려왔다고 하는데, 직역해서 “각도”, “관점”이라고 이해해도 무리없을 것 같다.
This is achieved through angles, which are arguments for a narrative interpretation of events based on selected data, and are influenced by Roger Schank’s thematic structures (1982). from StatsMonkey: A Data-Drived Sports Narrative Writer
야구 경기 소식을 전하는 기사에서 발견되는 관점(스토리라인)을 분석해보면 그 종류가 엄청나게 다양하지는 않을 것이다. 어느 팀이 경기 내내 리드하면서 이겼다거나, 역전승을 거뒀다거나, 엎치락뒤치락하다가 비겼다거나, 누가 완벽한 투구를 했다거나, 누가 어떤 기록을 세웠다거나 등. 손가락으로 셀 정도는 아니지만 소설같은 장르에 비할 바는 아니다. 그래서 미리 이런 관점들을 준비해 놓았다가 상황에 맞게 갖다 쓰는 방식으로 보인다. (“상황에 맞게”는 “적당히” 만큼이나 어려운 일인데, Win Probability나 Leverage Index 같은 요소와 Angle을 매칭시키는 기술력이 경쟁력일 것이다.)
물론, 한 경기에 하나의 관점만 있는 것은 아니다. 각 관점에 우선순위를 매겨서 여러 개를 조합하게 되면 다양한 경우의 수가 생기므로 글의 내용이 다채롭고 풍부해질 수 있다.
마지막 단계는 진짜 문장을 쓰는 것이다. 간단한 설명만 보고 추측하건대, 종류 별로 대본을 만들어놓고 숫자를 그때그때 채워넣는 방식인 듯하다. 이 부분은 거창한 연구거리는 아닐지 몰라도 실제 서비스를 하려면 가장 손이 많이 가고 신경쓰이는 과정일 것이다. 문장이 너무 단조롭거나 비슷한 패턴이 반복되지 않으면서 어색함이나 오류가 없어야 하니까 말이다.
스포츠와 주식 뉴스를 타겟으로 삼은 이유 중 하나는 이들 주제의 기사는 대체로 정형화된 틀이 있기 때문이다. 문단의 구조나 문장 스타일을 컴퓨터로 흉내내도 그럴 듯한 기사를 쓸 수 있다. 또 다른 이유로는 기사의 소재가 되는 데이터가 잘 구조화되어 있다는 점을 들 수 있다. 기계적이고 정량적인 방법으로 스토리의 플롯을 짜낼 수 있기 때문이다.
어쨌든 제한된 도메인에서라도 자동화된 기사 작성이 보급되면 앞으로 어떤 파급효과를 가져올지 궁금하다. 당장 이런 기사를 작성해오던 기자들은 단순한 데이터 정리 업무에서 어느 정도 해방되어 좀더 심층적이거나 새로운 관점의 기사를 쓸 여유가 생길 것이다. 다르게 말하면, 자기만의 고유한 관점과 해설을 제시할 수 없는 기자는 경쟁력을 잃게 될 것이다.
개인적으로 이런 기술에 관심을 갖는 이유는 똑같은 대상에 대해서 독자에 따라 맞춤형 기사를 작성할 수 있다는 점 때문이다. 단순한 예로, 경기 결과를 전할 때 이긴 팀의 팬에게는 “짜릿한 역전승을 거뒀다”고 하고, 패한 팀의 팬에게는 “아쉽게 역전을 허용했다”라고 쓸 수 있다. 또 투수 피칭에 관심 많은 팬에게는 투구 내용 관점의 기사를 보여주고, 또 상대적으로 덜 유명한 선수의 플레이 중심으로 기사를 쓸 수도 있다. 검색 패러다임에서는 누군가가 이미 써놓은 글을 잘 찾는 게 경쟁력이지만 이제는 사용자가 요청하면 알고리즘이 직접 답를 만들어서 보여주는 세상으로 들어가는 길목에 있는지도 모르겠다.